


[box type=’info’]As the Technical Coordinator of the Search Marketing and Advertising team at TechSmith Corporation(if you’ve ever watched a screencast you’ve seen their software in action), a software company in Okemos, Michigan, Chris Bawden is responsible for Analytics and the technical aspects of SEO. In doing so, he spiders the website daily, so we asked him for a few insights on how he handles his reports. Here’s what he said.[/box]
When running site audits and investigating unfamiliar sites, it can be tricky to understand what’s happening in the environment. Usually I configure my spiders to exclude parameters so that I’m able to attack on-page SEO in an organized fashion. But when I need to evaluate the site structure and the interaction between multiple systems, I let my spiders run wild across the site and grab everything they can find. I have found that you can learn a great deal about your site by examining the parameters themselves and comparing the URL variations of each page.
There might be times, however, when you just can’t get the right configuration or your spider won’t give you all the desired configuration options. As a result, your spider will often pick up multiple hits to the same page only with a slight URL variant… like pages with dynamic parameters.

You’ll often see these when using a 3rd party system and masking the domain, like a feedback platform or a job application portal. Sometimes you see these when using non-standard parameters, or when parameters change the page content. In some instances you’ll want to get rid of the variant URLs and only keep the base URLs, at other times you’ll want to filter them and analyze the parameters. So, how do you choose what to do? Here are a few tips on handling sider reports that all SEO professionals should know. First, export a list of all URLs from your spider. Dump them into Excel [or export with our crawler directly to .XLS] and sort the URL column A-Z. If you also export all metadata then you’ll want to insert a blank column to the right of the column with your URL list. Next use the Text-to-Column feature under the data tab to separate parameters from the URLs:

In the first step choose ‘Delimited’ file type.
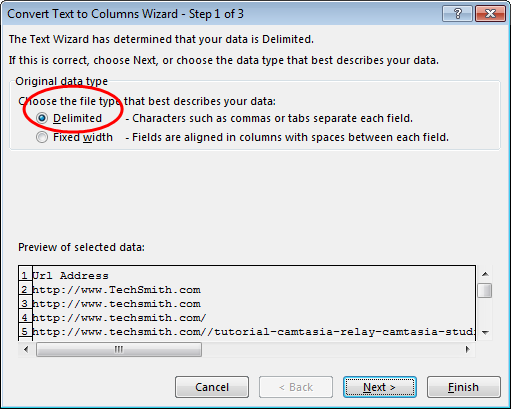
Next enter a ‘?’ as the delimiting character:
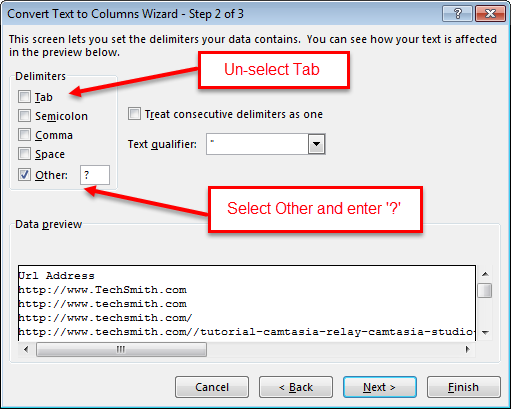
The next step in Excel allows you to format the data if you wish, but for this instance, there’s no need, just click Finish. Now you have the URLs in the left column and the parameters in the right column. You’ll likely have some duplicate URLs, but before you go pulling the de-duplication trigger, take a look at the parameters. You can get a good idea of what the parameters are used for with this isolated view, and you should also start getting some idea if the parameters are standardized or not. Once you get that figured out, you can begin to de-duplicate the URLs. Just select the column of URLs and hit ‘Remove Duplicates’ on the Data tab.

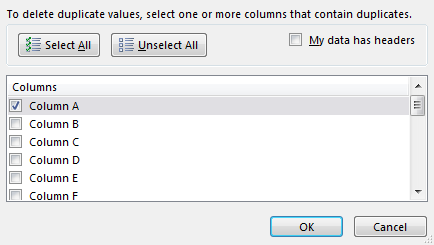
You can see from the image below that I have a lot of duplicates. This is likely due to a large amount of non-standardized, dynamic, or unrecognized parameters. I should probably standardize my parameters (good thing this is an old report and I already have).
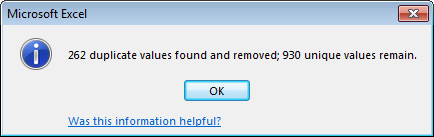
When de-duplicating with Excel, only the top value of a duplicate set is preserved. So if you de-duplicate the below table on the left based on the value in the Page column, you will end up with the below table on the right:
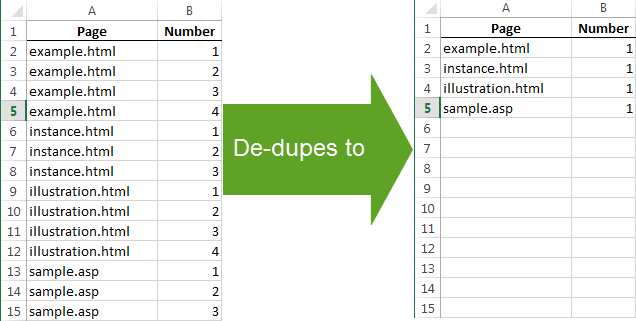
That means if you had sorted the URL column from A-Z in the first step, the original URL with no parameters would be the top value in the duplicate set and all of the real metadata would still be accessible. This is important because quite often spiders can’t pick up all of the metadata when listing a page’s URL variation, so this technique cleans up your reports quite a bit.
But, let’s say you want a report of only your URLs with parameters. That’s easy. Instead of de-duplicating, just sort the parameter column A-Z or largest-smallest then copy and paste to a new tab.
Why would you want to do that? Sometimes adding a canonical tag isn’t enough, so you need to stop the parameters or URL variations at the source. Sometimes forms are pre-populated by passing values into the URL from the link, and sometimes visitors are redirected based on parameters that are added. This parameter report can give you a list of referrers and in-links to give you an idea where these non-standard burrs are attaching themselves.
For many of you, the above exercise seems simple. None-the-less, I practice this every week because the same techniques can be applied to all types of reports, like organizing download reports from my Content Distribution Network by their file type or filtering the domains from my list of email leads (I use the ‘@’ symbol for the delimited character instead of a ‘?’).
Spiders are great, but they’re only as great as your SEO skills, so first you need to master the fundamentals. None of the violation reports or crawl diagnostic commands matter if you can’t analyze the most basic of data sets and put the results to work. I suggest you take this technique and try filtering different fields. Try de-duping based on meta-keywords for a count of unique keyword sets on your site. You could also use the text-to-column feature on the file types of your pages to see how many HTML and asp pages you have. Test your SEO intuition and try something new!
Happy filtering and please reach out to me on Twitter to share the insights you find!
Trish
26 . Feb . 2015Is there anyway in WebCrawler to omit URL parameters from the crawl? My problem is is that the site I’m trying to crawl uses so many url parameters that the report never finishes.
William Gomes
06 . Apr . 2015Hi Trish, this feature has actually already been created and will be in a future version of our crawler. I’ll let you know when 😉