


[box type=’info’]Chris Bawden is a SEO celebrity in the making you can find him at: CRBawden.com check it out for more great posts. Chris had some problems recently while boldly crawling where nobody crawled before. He shares his experiences below:[/box]
Web crawlers are one of the most important tools an SEO has in his or her tool bag. Crawlers are also some of the most powerful tools that SEOs wield, so it’s important understand how to use them responsibly. You may wonder how much damage can actually be done with a crawler; the answer is that quite a lot of damage can be done if you aren’t paying attention. I recently received a message that looked something like this.
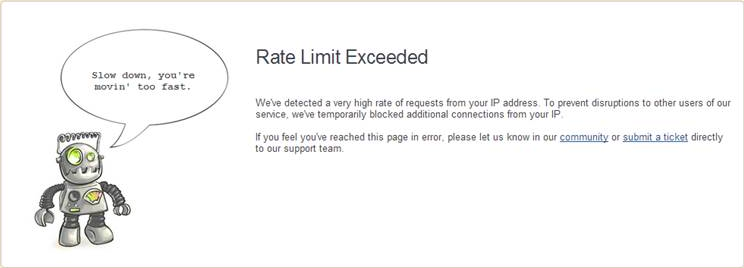
Don’t let his scare you though, a few simple adjustments and you won’t face the scrutiny of locking yourself or your clients out of your vital platforms.
First, let’s understand why this can happen. Similar to a human visitor, a crawler must call a web page to access the code that is on it. Every web page call is strain on the server, a few pages won’t have much effect but as hundreds of pages are called quickly the server is strained harder. This can cause problems.
First, if your server isn’t powerful enough, or if you share your server with other websites that are receiving traffic, a large number of page calls could slow down the server performance and increase page load time. KISSmetrics suggests that 40% of people will abandon a page if it takes over 3 seconds to load, and that a 1 second delay in page response can result in a 7% drop in conversions, so it’s important to monitor your response time and not run procedures that will jeopardize user experience. In the worst case scenario you could bring down the server entirely.
Many third party platform providers (such as feedback sites, forums, ecommerce platforms, or user account systems) are aware of these effects and will monitor the number of page calls from each IP address. If the crawler moves too fast, and too many pages are called within a short amount of time, all requests from that IP address will be blocked, thus preventing you or your client from viewing pages on that platform.
As I mentioned above, however, there are easy ways to avoid jamming up your server or locking yourself out of a platform. Most locally hosted crawlers will allow you to set a crawl speed. By reducing the number of concurrent threads that your crawler will run at once you can slow down the speed and prevent too many pages from being called at the same time.
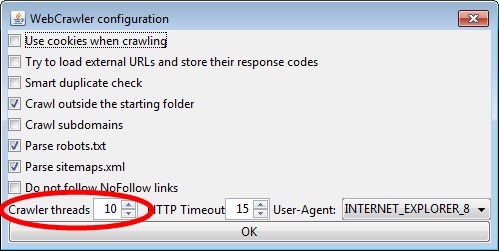
Conversely, you can increase the number of concurrent threads if you wish to complete your crawl more quickly, but I wouldn’t suggest doing this unless it’s truly necessary. Default is usually set between 5 and 10.
You can also set a crawl delay on your robots.txt file, this way you can specify an exact speed for the a crawler to operate. This is a little more difficult because you will first have to configure the crawler to adhere to the robots.txt file, then you will need to edit your robots.txt with the correct crawler name and the proper syntax. Here’s how the configuration should look:

The crawl delay value of 5 instructs the crawler to wait 5 seconds between each request to the server. Most legitimate crawlers and bots will adhere to these instructions, unfortunately spam bots will not heed these requests. If you prefer all crawlers adhere to this crawl speed limit you can use a wildcard in your user-agent instruction like this: “User-agent: *”, but that will also slow down important crawlers such as Google Bot and Bing Bot. Unfortunately though delaying Beam Us Up crawler won’t work as it doesn’t support crawl delay. Nudge nudge wink wink 😉
Hey! Just wanted to let you all know that we’ll be adding a new feature to our software that will support delaying the crawler speed very soon! – William Gomes of Beam Us Up
Ben
31 . Dec . 2016Just so you know, Google specifically indicates they treat the crawl rate in a toxic manner:
https://support.google.com/webmasters/answer/48620?hl=en
Daemon Harry
26 . Oct . 2018Please how do I generate a better robots.text so as to get index every minutes of published?
William Gomes
06 . Apr . 2020Whatever settings you put in it to make it faster won’t help. Google decides it itself based on how popular your website is / how often you update it.