
When you have a site and you want to improve your ability to rank in Google, many experienced SEO consultants and agency folk will turn to an SEO crawler. This is because while long-term success on your site depends on increasing your site’s authority through links, and reach potential customers by crafting quality content, you can often solve some technical SEO issues that will unlock additional traffic.
I’ve personally done more than a hundred SEO audits, using a variety of different SEO crawling tools.
The problem is that an SEO crawler will just provide you with data. Valuable data for sure, but just like showing my 10 year old the current stock market data, it doesn’t guarantee that anything productive can be done with it. The biggest issue is deciding on PRIORITY.
TIME OUT! Definition: An SEO crawler is software that can be cloud-based or downloadable, and it behaves like a search engine spider program. It emulates that behavior and accessess all the pages on your site, and compiles data like meta titles, meta descriptions, error codes and more for you to analyze. Putting clarification here because SEOs, freelancers and agencies might "do an SEO audit", and sometimes a crawl tool is called an "SEO auditor". The reality is that an SEO audit is a more detailed process, but very much relies on insights and data found in that "crawl". OK! GAME ON!
What’s Actionable Data From An SEO Crawl?
What exactly ARE the most actionable errors or problems to tackle when you’re reviewing the results of your SEO crawl? We’re going to get insights from tons of SEO experts, and see if at the end of the day, we can grab a hold of a method for you to make your site audit data more actionable.
Generally there are a few things to take into account with first time crawls:
Peter Mindenhall – Arclite SEO Solutions
Can it be crawled?
Should it be crawled?
Will it render?
If it can’t be crawled but should be? Fix that.
If it’s crawlable but it shouldn’t be (i.e. staging environment)? Fix that.
Can it be rendered/is the content visible from a crawling perspective? If it can’t and it should be then fix it!

“The main things I’m looking for when completing an SEO crawl are things that are holding back the site’s growth potential. In other words, the things stopping the site from ranking as strong as it should be if these issues didn’t exist.
“I very much hold the viewpoint that technical SEO gets overcomplicated, often looking to fix things that aren’t actually an issue in the first place. At least, not in the sense that they’re going to drive significant growth in rankings, traffic and resultant revenue.“At the most basic level, a page must be crawlable and indexable in order to be eligible to rank. So that’s where I start, by analysing the pages that are and aren’t crawlable and indexable. I’m looking to find issues where pages cannot be crawled or indexed when they should be or the flip where they can be but shouldn’t. It might sound like the basics, but it always surprises me how often I find issues here.
“After this, I’m looking for duplicate versions of pages; for example, products that exist on two or more different URL paths if working with an eCommerce store. These often occur as a result of missing canonicalisation.
“When I’ve completed a crawl, the first things I’m looking for are often the basics. I’m all for getting these things right and set up correctly before looking at anything more advanced, especially given that there are so many wins to be had by doing the basics better than others. It’s also, in my experience, where lots of sites fall down.”
James Brockbank, Managing Director & Founder of Digitaloft, comments:
I love these insights from both Peter and James, because it isn't actually a specific "category" of problems to handle, but the duality of crawl: To be crawled, or not to be crawled. That is the SEO question. Whether tis nobler of robots.txt to disallow, or meta to "noindex"/"nofollow". To suffer the slings and arrows of outrageous Google Search Console errors, or to configure one's HREFLANG correctly the first time. This suggests that the most actionable data in an SEO crawl is simply the list of pages that can be crawled vs the pages that cannot be crawled. Compare the two with your site, and determine if you've got it right or need to make changes to robots.txt files or "noindex" directives at the page level. - Jeremy
Any crawl? If so, first thing for me would be a gut check if the number of indexable pages matches what should be available on the client site, or what’s reasonably indexed in Google.
Cyrus Shephard of Zyppy
Small differences are fine, but if it’s orders of magnitude different, we might have a problem.
Next, I think most people would say “HTTP Status Codes” are important. While I don’t disagree, my next priority is typically scanning URL + titles, along with site structure, simply to see if anything is out of place.
If lots of weird pages are getting crawled, or if anything looks weird, it’s usually worth investigating.
Looking that the number of pages in your crawl, vs the posts/pages in your CMS is a good start, and looking for weird URL structures in your crawl is a great next step to actually identify what's not configured correctly! - Jeremy
SEO Fundamentals: Fix Broken Links
Sheralyn Guilleminot expert in Healthcare Content Marketing
- I look for broken internal and external links so I can update them (or remove the link entirely if a good alternative destination isn’t available).
- Look for redirect chains and prioritize fixing the ones that are too long.
1. Broken internal links: looks pointing to redirected or broken URLs are an easy gimme
2. Broken URLs generally: you could have valuable external links pointing to broken URLs. Reinstating or redirecting those URLs is another easy win.
Andrew of Optimisey
Andrew makes a great point, that you should also verify or cross reference with Google Search Console data, outside of a crawler, if you have external links that USED to point to resources, so you can salvage that value or traffic! - Jeremy
Ray Martinez
- Server response codes (Internal 404s, 301s, etc.)
- Canonical tags
IF IT'S BROKE FIX IT. Aside from the content displaying on pages, one of the fundamental parts of a site is the hyperlinks between pages. Keep in mind that there's actually surprisingly more than 3 WAYS though to fix links that are giving 404 eror codes. - Jeremy
1. 4xx & 5xx errors – these are the most pressing errors to address, in my opinion. Why create badass content for your customers (and Google) if they can’t get to it?! The same could really be said for redirect chains. Anything that keeps your content from being accessed is obviously NOT good.
Brie Anderson who does killer Analytics work.
2. On the other side of SEO, less technical perhaps, would be duplicate content. You want to offer unique content that completely fullfils a unique intent. Duplicate content is a great place to look for pieces that can be consilidated or, the opposite, just need to be expanded on.
Duplicate content IS an interesting topic in the crawl. While the early days of SEO had everyone afraid of some "duplicate content bogeyman", the reality is that it's more about wasting potential. The big advantage of a site crawl is that it lays out the bones, structure and architecture of your site. It's a good time to review what's actually useful for your business, and where you're spinning your wheels for no good reason! - Jeremy
1. Eliminate internal redirects: Page1 links to Page2.
Page2 redirects to Page3.
You should make it like Page1 -> Page32. Perform a “stress-test” of your website with your crawler.
Peter Nikolov of Mobilio Development
This means you adjust settings and do 10+ crawls per seconds. If errors 500/503 start to appear, this is bad sign. It indicates that your CMS/Ecommerce and hosting aren’t configured to handle high traffic periods.
Your hosting and CMS are an important part of your site's success but often they go unexamined or taken for granted until they cause a problem. Unfortunately, that's usually too late to avoid losing valuable traffic or rankings! It's a good idea to review your site's hosting capability, and a site crawler could be a tool to do a little "stress test". - Jeremy
Not Just Broken Links: Review Internal Links
1. Turning 404s with links into 301s.
2. Improving internal link structure.
Gyi Tsakalakis of EPL Digital
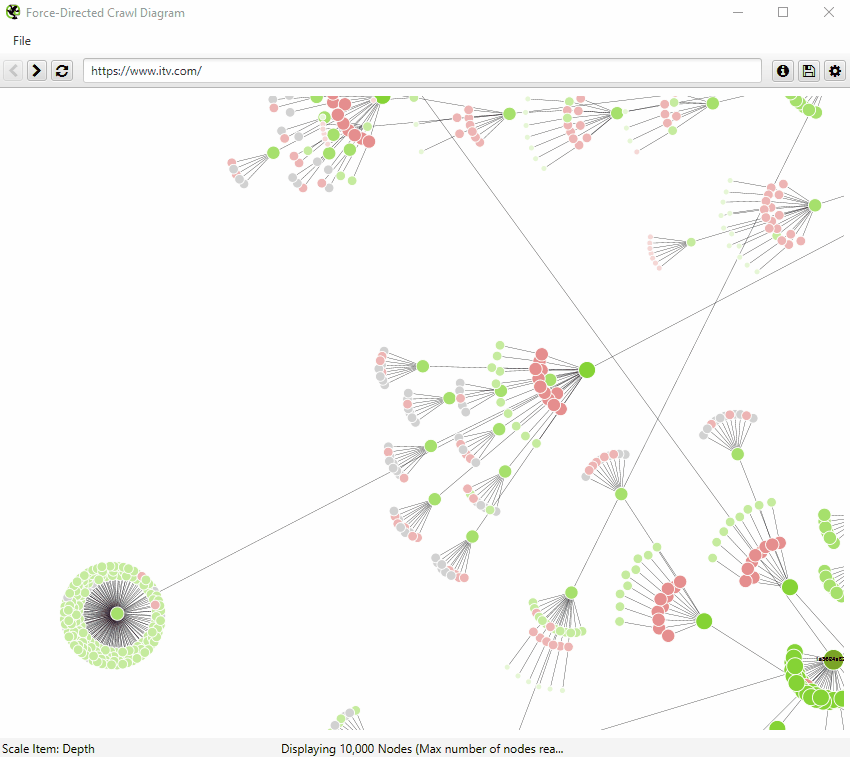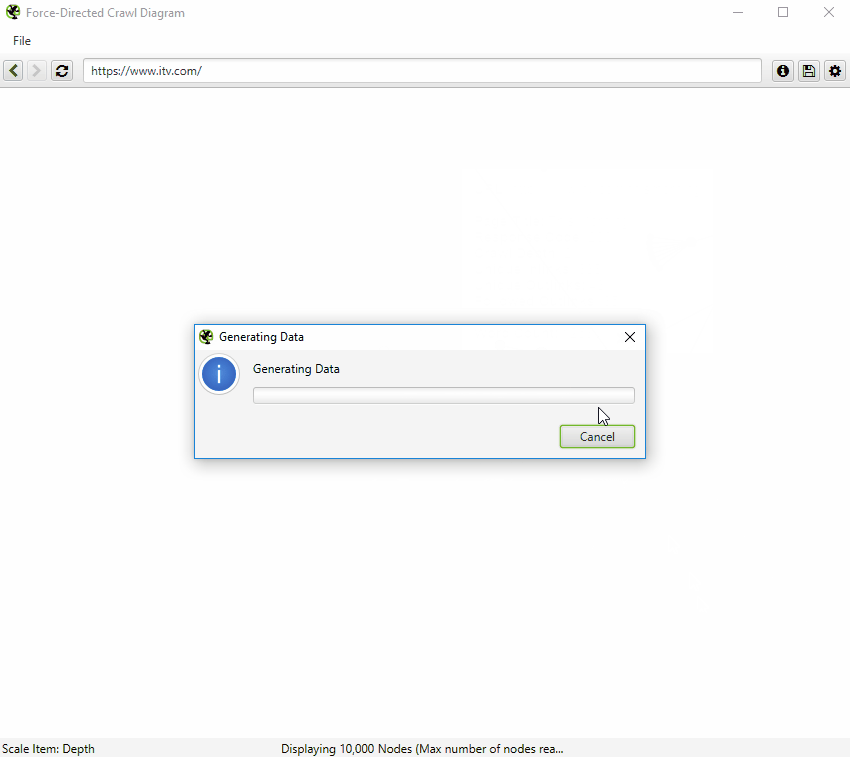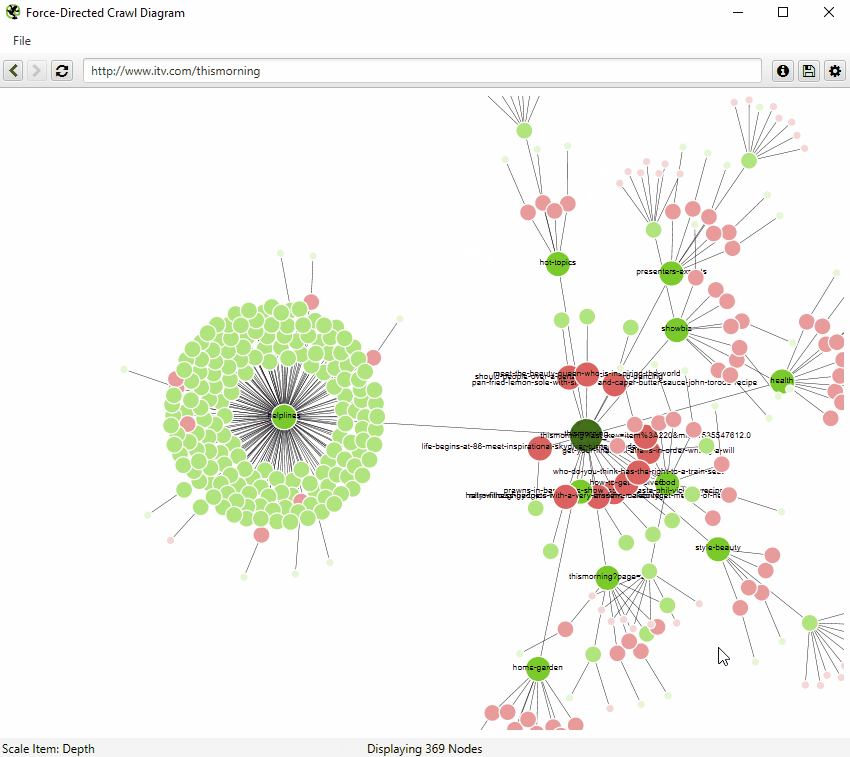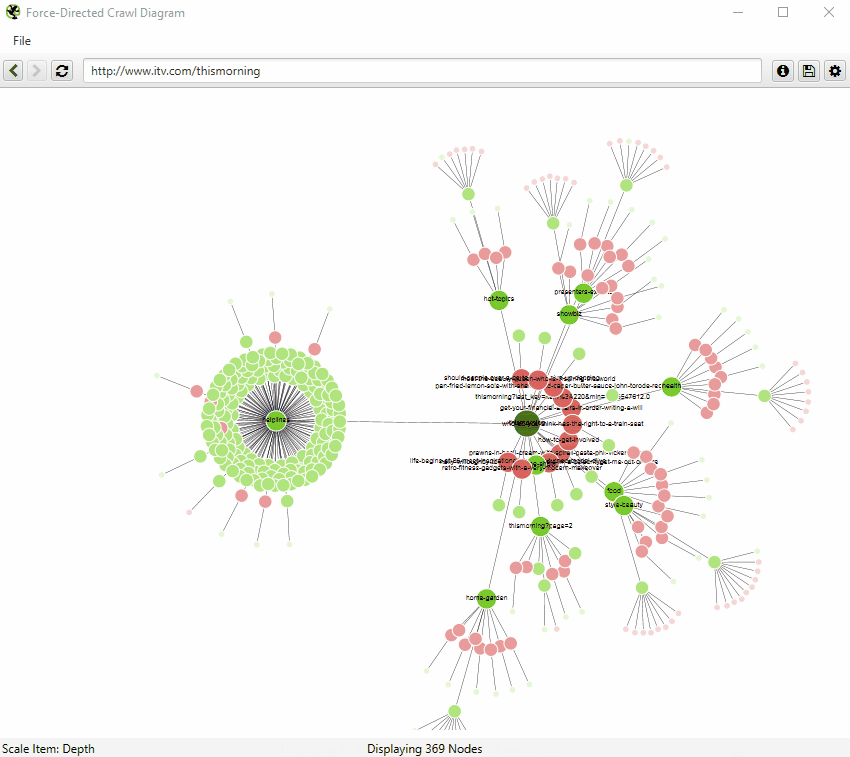
Just crawl?
Victor Pan
1. 404’s that should be fixed or redirected for a better user experience.
2. A force-directed tree diagram that shows internal linking importance. This lets you know which pages likely horde PageRank in the site’s structure, but you’ll have to corroborate with backlink data.
(Guide to visuals on Screaming Frog)
Canonicalised URLs that are serving a 200 HTTP response and are not paremeterised can be a symptom of a manually introduced error on your CMS. Look into it, fix it, establish a process to prevent it and measure the traffic gain.
Lidia Infante
My answer will be biased but I’d say internal links spread/distribution and labeling via custom extraction.
Marco Giordano of Seostistics
Outside of MarketMuse, using a crawler like Frog or using GSC data, internal linking structure is one of the most actionable data.
Jeff Coyle of MarketMuse
Cross referencing my topic authority data with my pages, and making sure my semantically similar pages are woven together is a simple, repeatable playbook.
I think the most actionable items are ones that can be addressed right away especially when there is limited dev support.
Bill Cutrer of Seapoint Digital
I usually look for internal broken links and spider traps that might churn up crawl budget on low-value content.
I also look for broken incoming links to redirect to high-value pages on the site.
Establish a Process for yourself:
Check for Outliers and Oddballs After a Crawl
After completing a site crawl, I first check what I call outliers and oddballs. (Incidentally, that also describes our SEO industry.)
Outliers include totals that are out of whack. Is the total page count way higher (or lower!) than expected? Is the total not in the ballpark of Google Search Console? Is the crawl running for so long my laptop is starting to smoke?
Absurd page counts often come from a particular section or template. Check if crawlers get bogged down by infinite combinations of attribute tags in a press release or research section, calendars that extend until the sun’s demise, or botched relative links that spiral out duplicate folders.
Are there surprise and outlier subdomains, such as leftovers from special events or projects?Puny page counts can indicate a problem in the other direction. Check pagination issues, such as JavaScript-only load-more buttons, and noindexed sections that weren’t flipped on when they went live.
Before I run a crawl in Screaming Frog, I set up custom searches to look for oddball content that shouldn’t be in production. Oddballs include:
Mark Alves SEO Expert
- utm_ codes (UTM tracking parameters should not be on your site to avoid complicating your analytics reporting.)
- Signs of artificial intelligence (AI) residue, such as regenerate response, large language model, and LLM.
- Lack of Google Analytics 4 (GA4) or Tag Manager snippets (sometimes special templates or subdomains lack these).
- The presence of staging URLs, such as WPEngine or Pantheon, in production.
- Placeholder text that doesn’t belong in production, such as lorem ipsum, tk (ancient copywriting abbreviation for “to come”), dummy, goes here, and xxx or xyz.
... Wow, yea. What he said! - Jeremy
Bonus Audit & Crawl Tips:
Not all of the gathered advice fit neatly into just TWO items, here’s some additional useful insights in no particular, or attributed order.
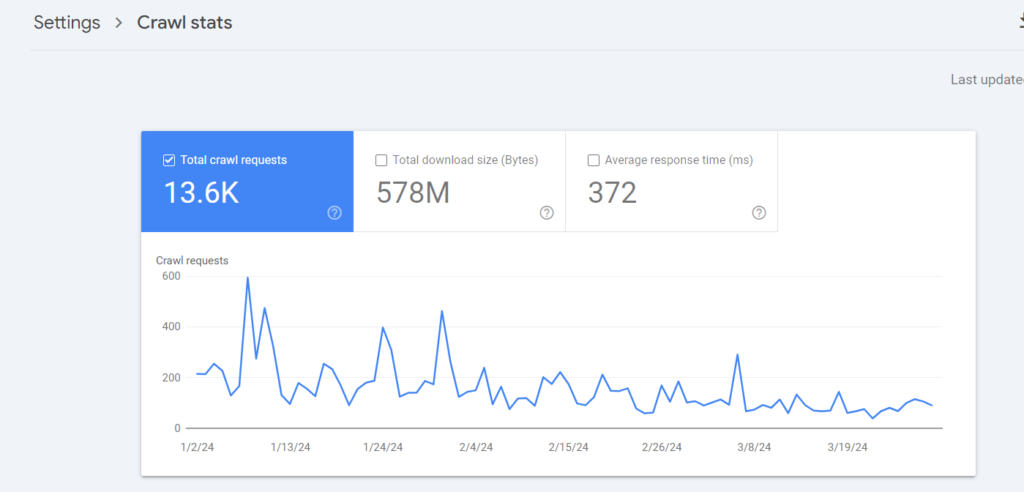
- GSC Crawl Report for weird errors. Specially on connectivity issues
- Combine crawl with log file analysis. This can help you to see strange patterns on your web site. Like most crawled web pages and less crawled web pages. And sections of your site where crawler isn’t crawl them yet.
- Make sure that analytics code is deployed to ALL pages on your site, don’t be blind!
- Fix broken user experiences and improve rankings on existing pages.
- Identify pages where adding helpful internal links may move rankings for less established pages.