


Download Windows, Mac or Linux
Remember you need Java installed for Mac (how to run on mac guide) & Linux. As well as to uninstall any previous version.
Installing on Mac Instructions
I unfortunately don’t have a Mac to test the Mac version however a user on Reddit has suggested to do the following:
Open Terminal (edit locations as required):
brew install openjdk
sudo ln -sfn /opt/homebrew/opt/openjdk/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk.jdk
java –add-exports java.desktop/com.apple.eawt=ALL-UNNAMED -jar /private/tmp/buu.jar
Need Support?
Reply to a comment with your real email address in this post and I’ll get back to you.
Whats in the update?
So we’ve been busy working on updates to Beam Us Up crawler the updates are many many many!
Crawls are automatically saved
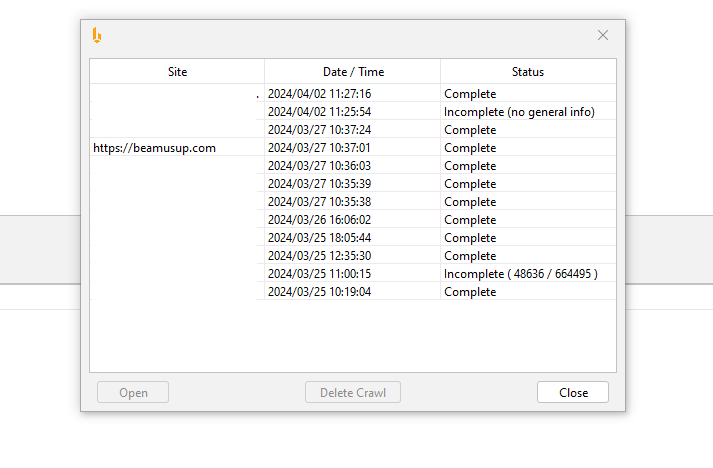
Crawling is saved periodically during a crawl.
If you crawl too many URLs and it freezes then and you restart the program it’ll load up from where you left off and you can complete it or delete it.
Right Click Copy
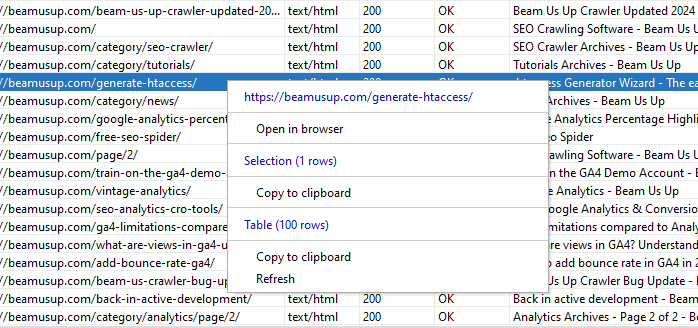
Lots of options to copy the tables.
Improvements in error filters
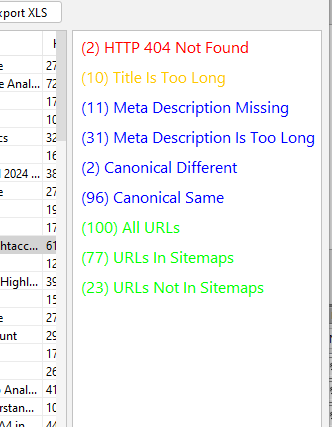
Color coded filters and cleaning up of the buttons
In and Outside of Sitemaps
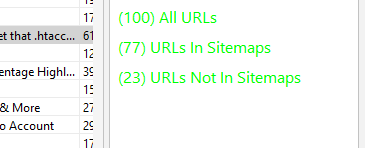
See if urls you are seeing are inside or outside of sitemaps.
Easier to see in links and out links from a page
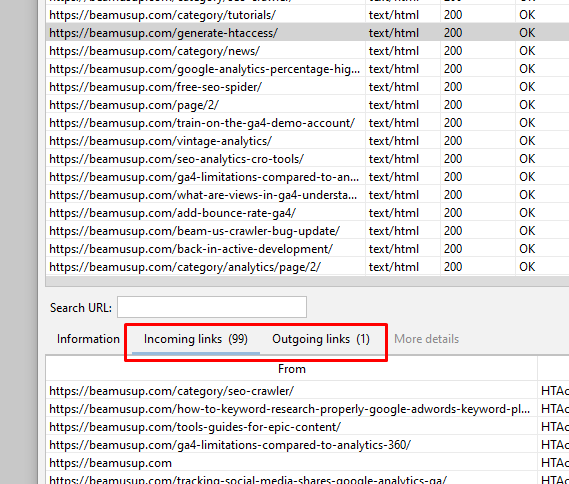
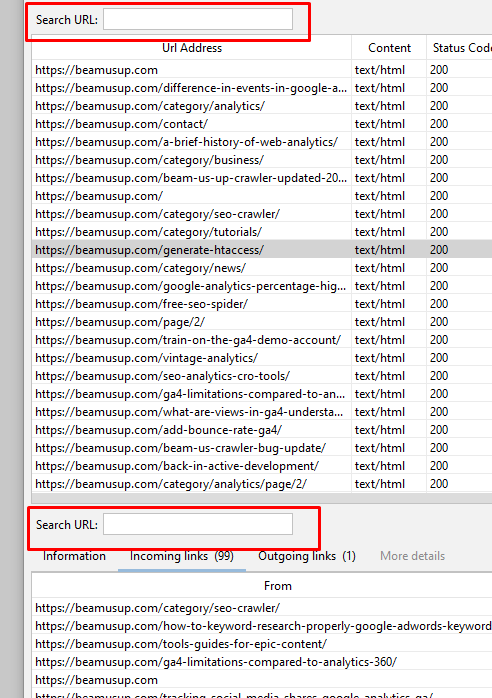
URL Search
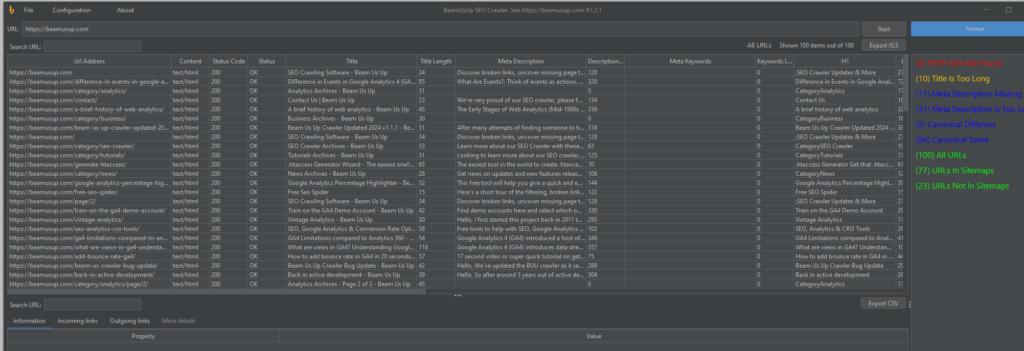
Dark Mode
Bug Fixes and Minor Improvements
A lot of bug fixes and minor improvements!
Ralf
03 . Apr . 2024Hi William,
thx a lot for the update! 🙂
Will test it out in the next days.
All the best!
Ralf
An
09 . Apr . 2024Have you tested it yet?
Mario
06 . Apr . 2024I tried to open the app in Mac with no success. I have the latest Java installed, but there is an error that doesn’t allow the app to open.
G
15 . Apr . 2024Hi Mario,
What error?
Thanks.
Thomas
17 . Apr . 2024Hey, I have same problem. Does anyone know how to fix it?
G
22 . Apr . 2024The error I am guessing is that it does not open. This is because of Mac’s overly aggressive “security”/wanting developers to pay them money. We have applied to Apple and we are currently trying to sign the DMG file to allow it to open easily. However it is a bit of a pain especially when we ourselves are not Mac developers.
Annie
09 . Apr . 2024Thank you for the update!
Adrian
10 . Apr . 2024Hello,
This is a nice upgrade!
I’m trying to crawl a big web (in development), so I’m getting two errors.
The first one:
Exception in thread “AWT-EventQueue-0” java.lang.ArrayIndexOutOfBoundsException: Index 800 out of bounds for length 800
at java.desktop/javax.swing.DefaultRowSorter.setModelToViewFromViewToModel(DefaultRowSorter.java:745)
…………..
The second one:
ERROR StatusLogger Log4j2 could not find a logging implementation. Please add log4j-core to the classpath. Using SimpleLogger to log to the console…
Finished (killed)
Regards
G
15 . Apr . 2024Hi Adrian,
Can you tell me what the operating system and website you are using is?
(If you reply with the website here don’t worry I’ll remove it from your comments before publishing so it’ll remain private ;))
Thanks.
Adrian
15 . Apr . 2024Hello, I’m using it in Debian 12 and the website is in local with docker.
The error comes because I got 144000 links and had not enough memory (16GB)… jeje So I think it was an error related no free memory (could not load it)
It would be good to have a check options about the “extra” filters (because as I notice, are all data, not related). So, if I don’t want to check about the “URLs Not in Sitemap” in this round, will be faster, because there is no need to check it.
Also, are you saving where am I comming from an URL? (as before, with a check option to do it, would be a good improvement). Sometimes is good to know which links points to “website.com/this-path”.
Thanks for your effort!
G
22 . Apr . 2024” are you saving where am I comming from an URL? ” Yes but the crawl needs to finish or you need to stop it and then it will calculate this.
114k urls is quite a lot. I doubt there are a lot of unique types of pages so I recommend you stop the crawl before it stops.
Hielke Brandsma
10 . Apr . 2024Hi Gui / William!
I really appreciate all your time and effort building this!
But .. I’m running into a small problem with retrieving content from our webshop The problem seems to have something to do with DNS. We use LightspeedHQ as webshop platform we are pointing the domainname to their servers, so from that point on, I’m unable to diagnose further. When I enter “our url” as URL, I only receive a HTTP 301 (Moved Permanently) message. I also found a CNAME in our DNS records: “7221.shops.oururl”, but this will be re-routed. I hope you have some answers for me, because I’m very curious 🙂
Thanks in advance!
Hielke
G
15 . Apr . 2024Thanks for letting me know I get the same issue will let you know if and when it is fixed 🙂
G
22 . Apr . 2024Fixed! Please uninstall and download again (assuming you are using windows if not then it isn’t fixed ;))
Eugene
22 . Apr . 2024Hello, tnx for app
Some new futures:
1) In Configuration check box – Do not crawl external domains
2) And also will be good to have info about missing Alt and Title tags for images
G
23 . Apr . 2024Hi Eugene,
1. This already exists
2. Good idea
Thanks.
Daniel
30 . May . 2024Hello 🙂 Thanks for the very useful BeamUsUp crawlerl, I recommended it to some colleagues who are more at the beginners stage and get overwhelmed with all the options of SF. This was simpler and the colour coding helped. Just wondering, is there a way your tool can crawl JavaScript sites? As in when you switch Rendering to JS in the other tool, or is this not possible? Thanks again.
G
28 . Jun . 2024Hi Daniel, thanks I appreciate it. Unfortunately adding that now is too complicated. Thanks
Ado Cehic
05 . Jul . 2024Hey! I’m running into an issue with the latest version on MacOS. I’ve got an Intel Mac running 13.6.7, and the Java (Running the latest available version 8_411) error I get is the following:
Exception in thread “main” java.lang.UnsupportedClassVersionError: com/beamusup/webcrawler/WebCrawler has been compiled by a more recent version of the Java Runtime (class file version 55.0), this version of the Java Runtime only recognizes class file versions up to 52.0
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:756)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:473)
at java.net.URLClassLoader.access$100(URLClassLoader.java:74)
at java.net.URLClassLoader$1.run(URLClassLoader.java:369)
at java.net.URLClassLoader$1.run(URLClassLoader.java:363)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:362)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:359)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:635)
G
13 . Jul . 2024Thanks for letting us know we’re looking into getting a fully signed mac DMG file although apple make it extremely difficult especially for us non mac developers 🙁
G
25 . Jul . 2024Hello, sorry I thought I had replied to this sooner. The Mac version unfortunately, I don’t have a Mac myself so debugging is very difficult we’re trying to get a signed DMG file instead but Apple unfortunately does not make it easy to do. Thanks.
Bryan Jarvis
24 . Jul . 2024Your tool is great! I did notice one thing.
<meta name="description" content="Discover …."
seems to be overwritten by twitter:description
<meta name="twitter:description" content="Another description …"
Thank you again!
G
25 . Jul . 2024Hi Bryan,
Thanks is the example from the same domain name as your email address or something else?
Thanks.
Alfred
25 . Jul . 2024Hi, I have been using this GREAT tool no for some weeks and i am extremely happy with this tool . There is one comment I would like to make, it seems that the tool only can work with one sitemap, in my case I have 2 sitemaps because of the size of the website.
For future references it would be helpful when you would be able to enter the path to the sitemaps that a website is using.
G
25 . Jul . 2024HI Alfred, thanks for the nice comments. Is your website the one from your email or something else? Thanks.
Florian
25 . Jul . 2024Hi,
Good tools, but when i want to crawl an URL like http://192.168.0.10:8000/ with custom Port, the custom port don’t used for discovered page when it’s link like /mapage.
(In local for dev ^^)
Thanks
G
25 . Jul . 2024Hi Florian,
This is something we can implement in the next version 🙂
Thanks
Alfred
26 . Jul . 2024Hi, William, –> Yes, it’s http://www.flowers.nl
Alfred
26 . Jul . 2024Hi William,
Ignore my comment about the 2 sitemaps. It turns out that the software (ShopFactory) I am using is overwriting the robots.txt file every time we update the website. Initially, it was written correctly in the robots.txt; however, due to the updates, it now only shows 1 sitemap instead of 2. So All good and I will keep using this great tool. Thanks
Andrea Bergamasco
29 . Jul . 2024Hi, I have trouble to run BUU on MacOS Sonoma, java 21.0.2
➜ $ java -jar buu.jar
Exception in thread “main” java.lang.IllegalAccessError: class com.beamusup.webcrawler.MacDockInit (in unnamed module @0x673ba40c) cannot access class com.apple.eawt.Application (in module java.desktop) because module java.desktop does not export com.apple.eawt to unnamed module @0x673ba40c
at com.beamusup.webcrawler.MacDockInit.(MacDockInit.java:10)
at com.beamusup.webcrawler.WebCrawler.(WebCrawler.java:40)
Thanks !
G
18 . Dec . 2024Hi Andrea,
Check install instructions above see if that helps.
Thanks.
Duane
23 . Aug . 2024Gui, your BeamUsUp Crawler is fantastic and basically everything I needed for my particular use case!
I literally had my wallet and CC out ready to buy Screaming Frog and saw another hit in my very disappointing “alternative to Screaming Frog” search and wasn’t even going to click on it…
But, it was the link to your program and am so glad I did!
(With that said, I will tell you my mom raised a really good worrier (I got it from her. We used to joke that if she woke up in the morning and didn’t have something to worry about she would be even more worried that she was forgetting something important to worry about!) and say I hope everything is fine with you and yours and that you are still actively working on this (I had some questions and suggestions and the “Contact Me” was a tad hard to understand (but the good news is I used BeamUsUp to analyze your site and found the comments section… HA!)
Thank you, again, Gui, for the great work!
Duane
G
04 . Oct . 2024Thanks Duane I appreciate it.
Alfred
09 . Sep . 2024It looks like that The program has difficulty With the <h1 class="" tags. The results I get messages that for some pages the tag is missing. at the same time the tags are also not found. However they are all there.
Dominik
13 . Sep . 2024Hi,
I’am trying to start beamusup on mac OS and running into a error meassage:
Exception in thread “main” java.lang.IllegalAccessError: class com.beamusup.webcrawler.MacDockInit (in unnamed module @0x4d740d85) cannot access class com.apple.eawt.Application (in module java.desktop) because module java.desktop does not export com.apple.eawt to unnamed module @0x4d740d85
at com.beamusup.webcrawler.MacDockInit.(MacDockInit.java:10)
at com.beamusup.webcrawler.WebCrawler.(WebCrawler.java:40)
I assume its the same issue like others have: Apple is a pain in the a** for some independend developers.
Best regards
Dominik
G
04 . Oct . 2024Hi Dominik,
Unfortunately as I don’t have a Mac myself I can’t help. In general though its because you need to manually through terminal allow the app to run. I think I’ll be removing the Mac version to be honest as it’s such a pain especially since I don’t have one myself.
Thanks.
Florian
16 . Sep . 2024Hi,
For the future update, if you can get sitemap from robots.txt (if the name is not sitemaps.xml) and if it’s you can scan accros multiple sitemap in sitemap index 🙂
Thanks
jaden
04 . Oct . 2024Pretty great work but when I am trying to crawl website it just shows done with robots and processed Robots.txt but nothing happens after that. it just stays like that and no results are shown.
G
04 . Oct . 2024Hi Jaden, can you tell me what the website is that you are trying to crawl? Thanks
Sol
08 . Oct . 2024Hello!
I’m trying to crawl in a website that is private (you have to login to entre the web). Is there any change to do this?
Thanks!
G
18 . Dec . 2024Hi Sol,
Unfortunately not sorry.
Thanks.
Jakub
14 . Oct . 2024It would be nice to edit max memory usage in app instead of editing config file 😉
G
18 . Dec . 2024Unfortunately that is too much effort for the benefit.
Thanks
Isaac
18 . Oct . 2024Hi,
I can’t seem to crawl the entirety of the website that I’m trying to crawl, it’s only crawling the pages directly linked to the URL I’ve entered. Could you please advise how I can crawl my website fully? Thanks.
G
18 . Dec . 2024Hi Isaac,
This is how search engines work also. But perhaps I am not fully understanding what you mean?
Thanks.
Rich Mellor
21 . Oct . 2024I think the crawler may ignore the base href tag, which means it generates 1000s of extra links if you are not careful
G
18 . Dec . 2024Hi Rich,
Can you please give me an example as on your website (from the email address) it works fine.
Thanks.
Michael R Youngblood
06 . Dec . 2024Yea, same here. On the latest MacOS update (15.1.1), Not able to open, Apple cannot verify if the program includes malware.
G
18 . Dec . 2024Hi Michael,
Did you try with the method described in the post above?
Thanks.
Brian Metis
02 . Feb . 2025Hello,
You say the service stores the records.
Which it does.
But where abouts does it store them in the folder and also in what format.
Thanks
G
03 . Feb . 2025Hey Brian,
In windows it is in:\.beamusup.com\buu\crawls
C:\Users\
The format isn’t anything standard.
Thanks.